
A brief introduction to Ceph
Last updated: 30-Apr-2016
Since the importance of continuous delivery tooling is growing, the requirements for availability and scalability also increase. Tools must be High Available so engineers can always deliver new software. But what does that mean? Basically you want your service to remain available, even when a component of that service fails. A component could for example be some kind of process. To make that more reliable you can run multiple instances of this process and loadbalance between them. A component can also be a collection of data. Data can be stored in a database or on a file system, or whatever, but it will end up on some kind of storage device, like an SSD, a Hard Drive or even a Tape.
The storage challenge
Many things can go wrong with storage. The storage device can break, the filesystem can get corrupt, the computer that is attached to the device can break, and so on, and so on. To avoid outages you would like to have multiple instances of all of these components. If something goes wrong, the other components must automatically take over. On top of that you would like your data to be both replicated and distributed, to avoid data loss. All of this should be done automatically, without any worries for the user. For the user it should simply act as one unit of storage. But you don't want to buy an expensive proprietary solution. It should all work on standard components, with open source software. So...is that possible? With Ceph it is!
What is Ceph?
 On Wikipedia it says:
Ceph is an object storage based free software storage platform
that stores data on a single distributed computer cluster,
and provides interfaces for object-, block- and file-level storage.
We'll take a closer look at what that means in a moment.
On Wikipedia it says:
Ceph is an object storage based free software storage platform
that stores data on a single distributed computer cluster,
and provides interfaces for object-, block- and file-level storage.
We'll take a closer look at what that means in a moment.
Ceph aims to provide scalabale storage, without a single point of failure. It is open source and freely available. Development of Ceph started in 2004. Since 2014 Ceph is owned by RedHat.
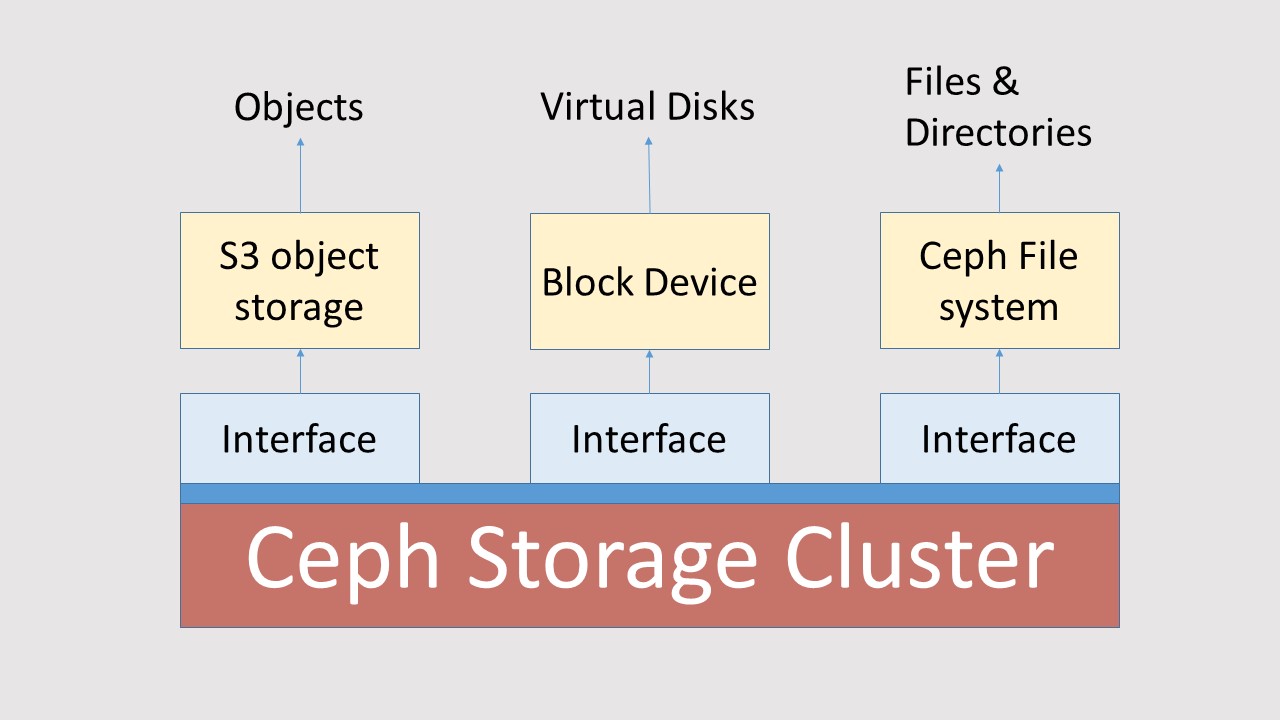
Ceph creates a cluster of storage, and transforms this cluster to an object store. This is called the Ceph Storage Cluster. Via interfaces the Ceph Storage Cluster delivers S3 object storage, Block Devices and File systems. Schematically that looks like the picture on the left.
How does it work?
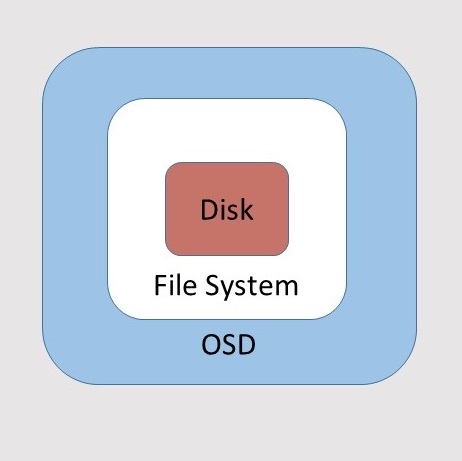
Suppose you have a number of disks with a file system installed on it. Ceph adds a software layer to this which is called an OSD which stands for Object Storage Daemon.
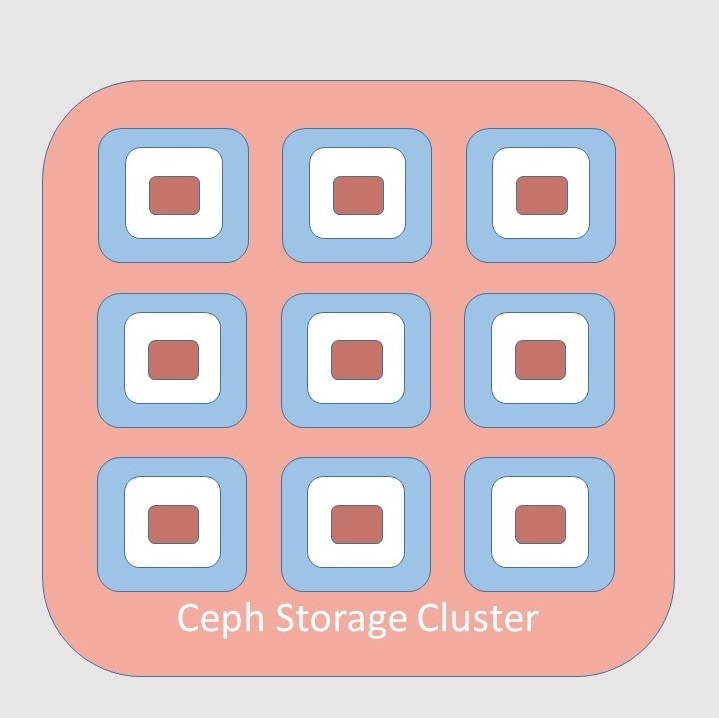
With the daemon installed, Ceph can add these disks to a Ceph cluster. The cluster will act as one big storage unit. The disks with the OSD in the cluster are called nodes. Based on specifications Ceph will replicate and distribute data amongst the nodes. This is also done by the OSD's.
A Ceph cluster can consist of thousands of nodes.

Ceph needs to keep track of the health of all the available nodes. This task is done by monitors. Monitors are nodes that do not hold any object data. However the monitors know exactly which nodes are part of the cluster, and what their status is (up, down). Note that the status of a note is determined by voting amongst the monitors. This is why you usually want a low number of nodes. (Say three).
The Ceph Storage Cluster a.k.a. the Ceph Object Store is called RADOS. This stands for Reliable Autonomous Distributed Object Store.
Architecture of Ceph
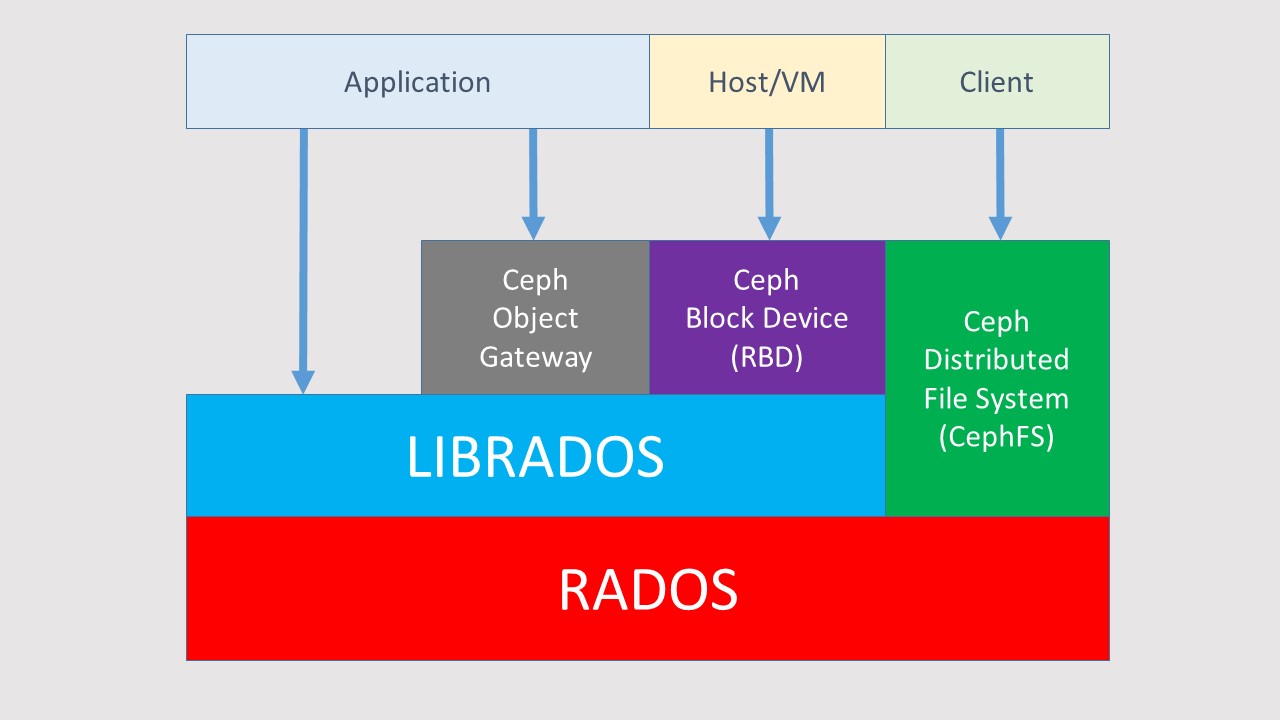
The fundament Ceph is built on is RADOS. On top of that Ceph provides interfaces to communicate with the Object Store. The first interface is LIBRADOS. This is a software library that provides direct access from an application to RADOS. The library supports many languages like Java, C++, Python and PHP.
If you want your application to access Ceph S3 storage, it needs to talk to RADOSGW. This is a REST gateway that uses LIBRADOS to access the Object Store.
If you want to add a Ceph Block Device (say a virtual disk) to your host or to a VM, you need to connect it to RBD (Rados Block Device). RBD again uses LIBRADOS to access the Object Store.
And finally you can create a Ceph File System. (CephFS) CephFS doesn't use LIBRADOS, but instead creates special nodes in the storage cluster that contain the metadata of the filesystem. (like permissions, directory hierarchy, mode, etc) Like the Monitor nodes, the Metadata servers as they are called, do not contain data for the Object Store.
Note: A more detailed explanation can be found on YouTube, where Ross Turk talks about the Architectural overview of Ceph.